مقدمه:
همانطور که می دانیم PostgreSQL پیشرفته ترین سیستم مدیریت پایگاه داده رابطه ای است. معماری PostgreSQL از دو مدل استفاده می کند:
- Client
- Server
Client درخواستی را به سرور PostgreSQL ارسال می کند و سرور PostgreSQL به درخواست Client پاسخ می دهد. در برنامه های معمولی، Client و Server روی ماشین های متفاوتی قرار دارند، آنها از طریق اتصال شبکه TCP/IP با هم ارتباط برقرار می کنند. سرور PostgreSQL چندین Session همزمان را از Client مدیریت می کند. برای رسیدن به این هدف با شروع یک فرآیند جدید برای هر اتصال. از آن نقطه، فرآیند Server جدید و Client بدون مداخله فرآیند دیگری با یکدیگر ارتباط برقرار می کنند. PostgreSQL دارای فرآیندهای پس زمینه( Background Processes) خود برای مدیریت سرور PostgreSQL است. معرفی پایگاه داده Postgresql
معماری پایگاه داده Postgresql:
ساختار فیزیکی PostgreSQL ساده است. از اجزای زیر تشکیل شده است:
- حافظه مشترک (Shared Memory)
- فرآیندهای پس زمینه (Background processes)
- ساختار دایرکتوری داده / فایل های داده (Data directory structure / Data files)
شکل زیر معماری PostgreSQL را نشان می دهد.
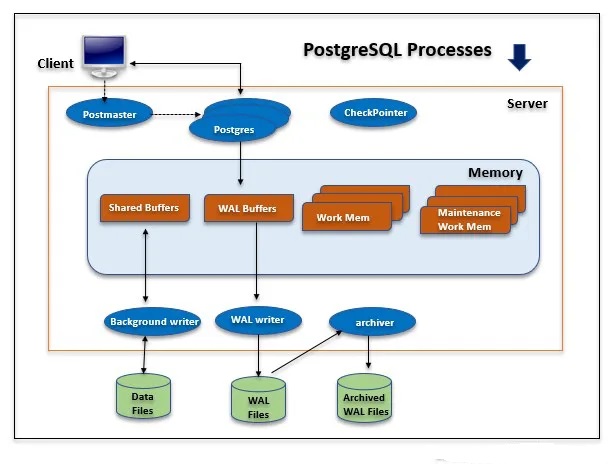
بررسی حافظه اشتراکی (Shared memory)
حافظه اشتراکی به حافظه ای اشاره دارد که برای تراکنش ها رزرو شده است، و یک لاگ دیگر را می گیرد. حافظه مشترک از اجزای زیر تشکیل شده است:
بافرهای مشترک (Shared Buffers)
ما باید مقداری از حافظه را برای استفاده از بافرهای مشترک روی یک سرور پایگاه داده تنظیم کنیم. مقدار پیشفرض بافرهای مشترک در 9.2 و نسخه قدیمیتر 32 مگابایت (32 مگابایت) است و از 9.3 مقدار پیشفرض بعدی بافرهای مشترک 128 مگابایت (128 مگابایت) می باشد.
اگر یک سرور اختصاصی برای PostgreSQL داشته باشیم، شروع معقول برای تنظیم مقدار بافرهای مشترک 25٪ از کل حافظه است. هدف از بافرهای مشترک به حداقل رساندن DISK IO سرور است.
بافرهای WAL(WAL Buffers) wal = write_Ahead logging
بافرهای WAL به طور موقت تغییرات را در پایگاه داده ذخیره می کنند، که تغییرات در بافرهای WAL در یک زمان از پیش تعیین شده در فایل WAL نوشته می شود. بافرهای WAL و فایلهای WAL برای بازیابی دادهها در اوج زمان در زمان پشتیبانگیری و بازیابی بسیار مهم هستند.
حداقل مقدار بافرهای مشترک 32 کیلوبایت است. اگر این پارامتر را wal_buffers برابر با -1 قرار دهیم، بر اساس shared_buffers تنظیم می شود.
حافظه کاری (Work Memory)
حافظه خاص را روی اتصالات هر کلاینت تنظیم کنید تا توسط عملیات مرتب سازی داخلی و جداول هش برای نوشتن داده ها در فایل های دیسک موقت استفاده شود.
مقدار پیشفرض حافظه کاری در 9.3 و نسخه قدیمیتر 1 مگابایت (1 مگابایت) است و از 9.4 مقدار پیشفرض بعدی حافظه کاری 4 مگابایت (4 مگابایت) می باشد.
حافظه کاری تعمیر و نگهداری (Maintenance Work Memory)
ما باید حداکثر مقدار حافظه را برای عملیات نگهداری پایگاه داده مانند VACUUM، ANALYZE، ALTER TABLE، CREATE INDEX، ADD FOREIGN KEY و غیره مشخص کنیم.
مقدار پیشفرض حافظه کاری تعمیر و نگهداری در 9.3 و نسخه قدیمیتر 16 مگابایت (16 مگابایت) است و از 9.4 مقدار پیشفرض بعدی حافظه کاری تعمیر و نگهداری 64 مگابایت (64 مگابایت) می باشد.
بهتر است که حافظه کاری تعمیر و نگهداری در مقایسه با حافظه کاری بزرگ باشد. تنظیمات بزرگتر عملکرد تعمیر و نگهداری (VACUUM، ANALYZE، ALTER TABLE، CREATE INDEX، و ADD FOREIGN KEY و غیره) را بهبود می بخشد.
فرآیندهای پس زمینه (Background Processes)
در زیر فرآیندهای پس زمینه PostgreSQL آمده است. هر فرآیند دارای ویژگی های جداگانه و داخلی PostgreSQL است. جزئیات هر فرآیند به شرح زیر توضیح داده می شود:
فرآیند نوشتن پسزمینه(Background Writer process): در نسخه PostgreSQL 9.1، پسزمینهنویس مرتباً پردازش checkpoint را انجام میدهد. اما در نسخه PostgreSQL 9.2 فرآیند checkpoint از فرآیند نوشتن پس زمینه جدا شد. گزارش ها و اطلاعات پشتیبان را به روز نگه می دارد.
WAL Writer: این فرآیند داده های WAL را در بافر WAL به صورت دوره ای می نویسد و آن را برای ذخیره سازی دائمی پاک می کند.
Logging Collector: به این فرآیند Logger نیز می گویند. یک بافر WAL در فایل WAL می نویسد.
Autovacuum Launcher: هنگامی که autovacuum فعال است، این فرآیند وظیفه دیمون autovacuum را دارد که عملیات خلاء را روی میزهای پف کرده انجام دهد. این فرآیند برای تجزیه و تحلیل جدول کامل به فرآیند جمعآوری آمار متکی است.
بایگانی کننده(Archiver): اگر حالت بایگانی را فعال کنیم، این فرآیند مسئولیت کپی کردن فایل های گزارش WAL را در یک دایرکتوری مشخص دارد.
Stats Collector: در این فرآیند، اطلاعات Statistics مانند pg_stat_activity و pg_stat_database جمع آوری می شود. اطلاعات از جمع آوری کننده آمار از طریق فایل های موقت به فرآیندهای درخواست ارسال می شود.
Checkpointer Process: در PostgreSQL 9.2 و نسخه های بعدی فرآیند checkpoint انجام می شود. کار واقعی این فرآیند به این صورت است که وقتی یک checkpoint رخ می دهد، بافر کثیف را در یک فایل می نویسد.
Checkpointer: Checkpointer تمام صفحات کثیف را از حافظه به دیسک می نویسد و ناحیه بافر مشترک را تمیز می کند. اگر پایگاه داده PostgreSQL از کار بیفتد، می توانیم از دست دادن داده ها را بین آخرین زمان checkpoint و زمان توقف PostgreSQL اندازه گیری کنیم. هنگامی که فرمان به صورت دستی اجرا می شود، فرماندهی checkpoint یک checkpoint فوری را اجرا می کند. فقط ابرکاربر پایگاه داده می تواند checkpoint را فراخوانی کند.
Checkpoint در سناریوهای زیر رخ خواهد داد:
- صفحات کثیف هستند
- راه اندازی و راه اندازی مجدد سرور DB (pg_ctl STOP | RESTART).
- Commit
- شروع پشتیبان گیری از پایگاه داده (pg_start_backup).
- توقف پشتیبان گیری از پایگاه داده (pg_stop_backup).
- ایجاد پایگاه داده
فایل های داده / ساختار دایرکتوری داده ها (Data Files / Data Directory Structure)
PostgreSQL از چندین پایگاه داده تشکیل شده است. به این کلاستر پایگاه داده می گویند. هنگامی که قالب پایگاه داده PostgreSQL را مقداردهی اولیه می کنیم، پایگاه داده template1 و Postgres ایجاد می شوند.
Template0 و template1 پایگاه داده های الگو برای ایجاد پایگاه داده جدید کاربر هستند که شامل جداول کاتالوگ سیستم است.
پایگاه داده کاربر، با شبیه سازی پایگاه داده template1 ایجاد می شود.
دایرکتوری PGDATA شامل چندین زیرشاخه است و فایل های کنترلی به شرح زیر است:
pg_version: حاوی اطلاعات نسخه پایگاه داده است.
base: شامل زیر شاخه های پایگاه داده.
global: حاوی جداول خوشه ای مانند pg_user.(جداولی که در کل کلاستر مشترک هستند)
pg_clog: حاوی وضعیت داده های تراکنش های Commit شده.
pg_multixact: حاوی دادههای وضعیت چند تراکنش (برای قفلهای ردیف مشترک استفاده میشود).
pg_notify: حاوی داده های وضعیت LISTEN/NOTIFY.
pg_serial: حاوی اطلاعاتی در مورد تراکنش های committed serializable است.
pg_snapshots: حاوی عکس های فوری صادر شده است.
pg_stat_tmp: حاوی فایل های موقت برای زیرسیستم آمار.
pg_subtrans: حاوی داده های وضعیت تراکنش فرعی است.
pg_tblspc: حاوی پیوندهای نمادین به tablespaces.( symbolic links to tablespaces)
pg_twophase: حاوی state files برای prepared transactions.
pg_xlog: حاوی فایلهای WAL (Write Ahead Log).
pid: این فایل حاوی شناسه پردازش postmaster فعلی (PID) است.
جمع بندی :
معماری PostgreSQL عمدتا به دو مدل مشتری و سرور تقسیم می شود. مشتری درخواستی را به سرور ارسال می کند. سرور PostgreSQL داده ها را با استفاده از بافرهای مشترک و فرآیندهای پس زمینه پردازش می کند و پاسخی را برای مشتری ارسال می کند. دایرکتوری داده حاوی فایل فیزیکی سرور پایگاه داده PostgreSQL است.


